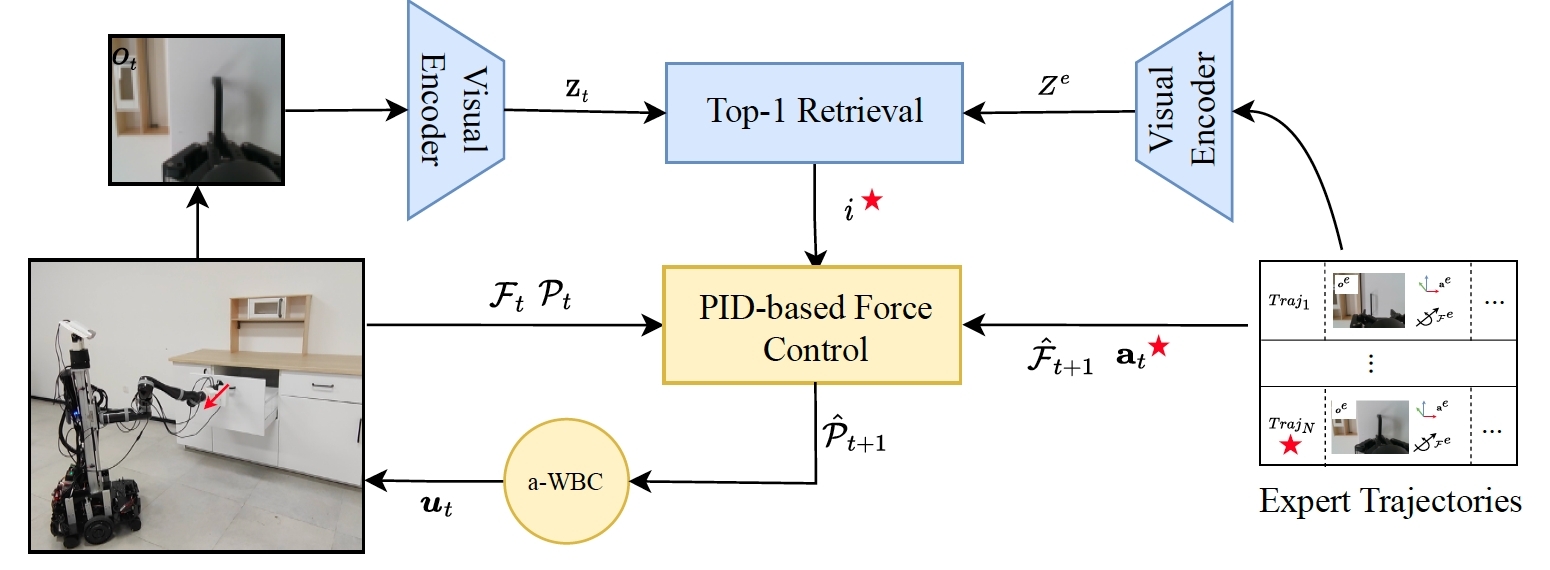
Behavior Cloning (BC)
Visual-Force Imitation
The observation images of the expert data are converted to representation vectors by a visual encoder. In
the rollout, the observation image is converted to a representation vector with the same visual encoder.
The action and target wrench are predicted by retrieving the action and wrench of the expert data with
top-1 similarity of the representations. We use admittance whole-body control (a-WBC) to control the robot.
The observation images of the expert data are converted to representation vectors by a visual encoder. In the rollout, the observation image is converted to a representation vector with the same visual encoder. The action and target wrench are predicted by retrieving the action and wrench of the expert data with top-1 similarity of the representations. We use admittance whole-body control (a-WBC) to control the robot.